Stop patching tools. Build real data systems.
An opinionated development ecosystem for ETL, APIs, and data platforms with full control and observability.
A Platform for Modern Data Engineering
Performance
Build efficient pipelines and services without unnecessary overhead.
We focus on real performance across the entire system, from data ingestion to processing and execution.
Clean Architecture
Design systems with clear boundaries and well-defined layers.
We apply proven engineering principles to build maintainable, testable, and scalable codebases that evolve without becoming complex
We build an opinionated development ecosystem for data systems. From ETL pipelines to APIs and distributed services, we provide the foundation to design, build, and operate scalable systems with clean architecture, strong typing, and full observability.
Observability
Understand what your systems are doing at any time.
Monitor pipelines, tasks, and services with built-in observability designed for debugging, reliability, and production readiness.
Full Control
Own your data stack end to end.
Run your pipelines and services wherever you need, with full control over infrastructure and execution.
Open Source Foundations
Our ecosystem is built on real, open-source foundations.
We design and maintain tools that bring clean architecture, performance, and observability to data systems.
Loom
A foundation for building APIs, microservices, and ETL pipelines with clean architecture, strong typing, and high performance.
Plywatch
Modern observability for Celery. Monitor tasks, understand dependencies, and debug workflows with real-time insights.
→ View GitHub
What We Are Building
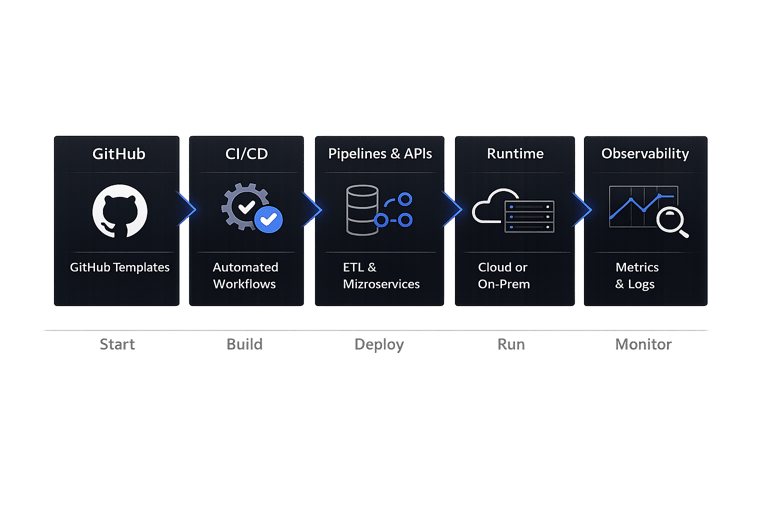
Start data systems with production-ready foundations from day one.
We are actively building a unified platform for developing and operating data systems.
From ETL pipelines to APIs and distributed services, our goal is to provide a production-ready foundation with clean architecture, strong typing, and built-in observability from the start.
The platform is designed to be cloud-agnostic, allowing systems to run across AWS, Azure, or custom infrastructure without vendor lock-in, while integrating seamlessly with modern data tools.
From GitHub templates and CI/CD workflows to runtime execution and monitoring, we aim to provide a complete development ecosystem to build, deploy, and operate data platforms with full control.